Regular Expressions
Regular Expressions တွေဟာ ဖိုင်တွေထဲက စာသားတွေကို ရှာဖွေဖို့ ဖော်ထုတ်ဖို့ရာ အားကောင်းလှတဲ့ ဒုတိယ Tool တစ်ခုပါ။ Patterns တွေတည်ဆောက်ပြီး ဖိုင်တွေထဲမှ စာသားတွေ အချက်အလက်တွေထုတ်ယူရာမှာ အလွန်ပဲ အသုံးဝင်ပါတယ်။ Scripts ဖိုင်တွေထဲမှာ (သို့) Perl (သို့) Python တို့လို High Level Languages Programs တွေထဲမှာ တွေ့ရလေ့ရှိပါတယ်။
Regular Expressions တွေသုံးတဲ့အခါ Character တိုင်းကို ထည့်သွင်းစဥ်းစားတာနှင့် String လို့ခေါ်တဲ့ Characters အတွဲလိုက်တွေ စကားစုတွေကို နှိုင်းယှဥ်တိုက်ကြည့်ဖို့၊ ရှာဖွေဖို့ ရည်ရွယ်ပြီး Pattern တွေ ရေးထားတယ်ဆိုတာတွေကို သတိပြုမိဖို့ အလွန်ပဲ အရေးကြီးပါတယ်။ Patterns အများစုဟာ Letters, Digits, Punctuation (သို့) Symbols တွေလို သာမန် ASCII Symbols တွေ အသုံးပြုပေမယ့် မည်သည့်စာသား ဘာသာစကားကိုမဆို တိုက်စစ်ဖို့အတွက် Unicode Characters တွေလည်း သုံးပါတယ်။
Patterns တွေ တည်ဆောက်ဖို့ Regular Expressions Meta-characters တွေကို ဖော်ပြပါမယ်။
| . | စာကြောင်းအလွတ် (Newline Character) မပါ မည်သည့် Single Character မဆို |
| [abcABC] | ထောင့်ကွင်းထဲရှိ မည်သည့် Character တစ်လုံးကို မဆို |
| [^abcABC] | ထောင့်ကွင်းထဲရှိ Characters တွေ မဟုတ်တဲ့ မည်သည့် Character တစ်လုံးကို မဆို |
| [a-z] | Range ထဲမှ မည်သည့် Character တစ်လုံးကို မဆို |
| sun|moon | ဖော်ပြထားတဲ့ စာသား စကားလုံး တစ်ခုမဟုတ်တစ်ခု |
| ^ | စာကြောင်းတကြောင်းရဲ့ အစ |
| $ | စာကြောင်းတကြောင်းရဲ့အဆုံး |
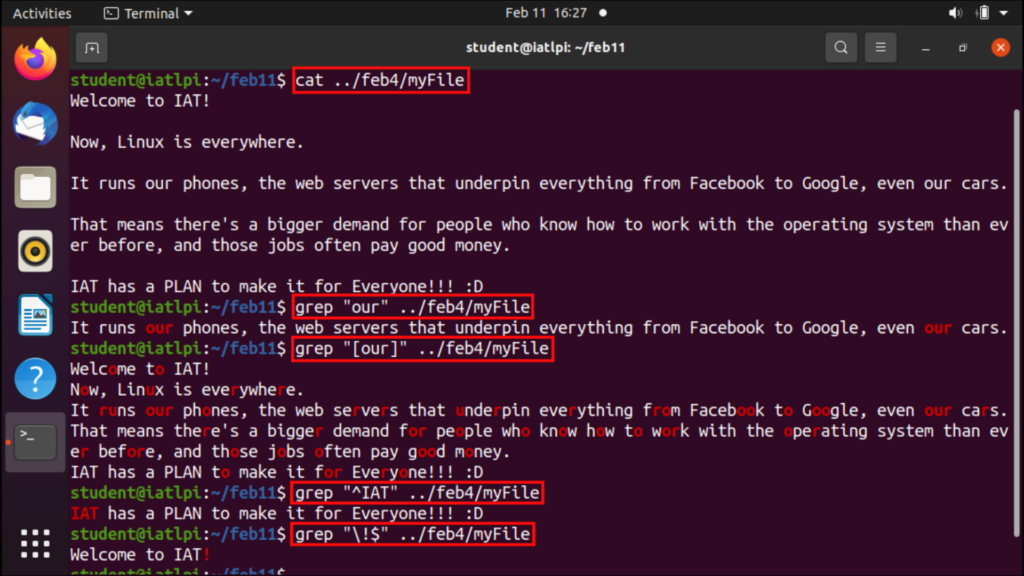
Regular Expressions Functions အားလုံးကို “grep” Command ဖြင့် တွဲပြီးလည်း အသုံးပြုနိုင်ပါတယ်။ “bash” ဆိုတဲ့ စာသားကို ရှာဖွေခဲ့တဲ့ ဥပမာမှာ Double Quotes တွေ ဝန်းရံပြီး အသုံးမပြုခဲ့တာ တွေ့မှာပါ။ Meta-character တွေကို Shell မှ Interpret မလုပ်ရအောင် ပိုမိုရှုပ်ထွေးတဲ့ Pattern တွေကို Double Quotes (“ ”) တွေဖြင့် ဖော်ပြသင့်တာပါ။ လေ့ကျင့်ဖို့အတွက် Regular Expressions တွေအတွက် Double Quotes တွေ သုံးပါမယ်။ အခြား Quotation Marks တွေဟာ ပြီးခဲ့တဲ့ အခန်းတွေမှာ ဖော်ပြခဲ့သလို သူတို့ရဲ့ မူလသာမန်လုပ်ဆောင်မှုတွေအတိုင်းပဲ ဖြစ်မှာပါ။
အောက်ပါ ဥပမာတွေမှာ Regular Expressions တွေ အလုပ်လုပ်ပုံတွေကို အလေးပေးဖော်ပြထားပါတယ်။ ဖိုင်တွေထဲမှာ Data တွေ ရှိနေဖို့ လိုတာမို့ မတူညီတဲ့ Strings အမျိုးမျိုးကို text.txt ဖိုင်ထဲကို ထည့်သွားမှာပါ။

ပထမ ဥပမာမှာ Regular Expressions မသုံးဘဲ/အသုံးပြုပြီး ရှာဖွေပြထားပါတယ်။ Regular Expressions တွေကို သေသေချာချာ နားလည်နိုင်ဖို့ ကွဲပြားမှုကိုသိဖို့ အလွန်အရေးကြီးပါတယ်။ ပထမ Command ဟာ စာကြောင်းတွေထဲမှာ အတိအကျတူတဲ့ စာသားကို လိုက်ရှာတာဖြစ်ပြီး၊ ဒုတိယ Command ကတော့ ထောင့်ကွင်းထဲက မည်သည့် Characters တွေမဆို ပါဝင်တဲ့ Characters တွေကို လိုက်ရှာတာပါ။ အဲ့ဒါကြောင့် Commands တွေရဲ့ ရလဒ်တွေက မတူကြပါဘူး။

ဒုတိယ ဥပမာမှာတော့ စာကြောင်းတကြောင်းရဲ့ အစနှင့်အဆုံးကို စစ်တဲ့ Meta-characters တွေ အသုံးပြုထားပါတယ်။ Regular Expression ထဲမှာ အစနှင့်အဆုံး Characters တွေကို နေရာမှန်အောင်ထားဖို့တော့ အရေးကြီးတာပါ။ စာကြောင်းတကြောင်းရဲ့အစကို စစ်လိုတဲ့အခါ Meta-character ကို Expression မတိုင်ခင်မှာထားဖို့လိုပြီး အဆုံးအတွက်တော့ Expression ပြီးတဲ့နောက်မှာ ထားရပါမယ်။

ဖော်ပြခဲ့ဖူးတဲ့ Meta-characters တွေလိုပဲ Regular Expressions တွေမှာလည်း သတ်မှတ်လိုက်တဲ့ Pattern ကို ဆပွားစစ်လို့ရမယ့် Meta-characters တွေရှိပါတယ်။
| * | ကပ်လျက်ရှေ့က ဖော်ပြထားတဲ့ Pattern မျိုး တကြိမ်မျှ ထပ်မပါတာ (သို့) အကြိမ်ကြိမ်ထပ်ပါတာ |
| + | ကပ်လျက်ရှေ့က ဖော်ပြထားတဲ့ Pattern မျိုး တကြိမ်မျှ ထပ်ပါတာ (သို့) အကြိမ်ကြိမ်ထပ်ပါတာ |
| ? | ကပ်လျက်ရှေ့က ဖော်ပြထားတဲ့ Pattern မျိုး တကြိမ်မျှ ထပ်မပါတာ (သို့) တစ်ကြိမ်ထပ်ပါတာ |
အခုလို ဆပွါးတိုးပြီးစစ်ပေးမယ့် Meta-characters တွေအတွက် ‘ab’ ပါဝင်တဲ့ String ကို တကြိမ်ပါဝင်တာနှင့် တကြိမ် (သို့) အကြိမ်ကြိမ်ပါဝင်တာတွေရဲ့ ရှာဖွေပုံတွေ ပြထားပါတယ်။ ရလဒ်မှာ “grep” Command ဟာ “abbb” ဆိုတဲ့ အပိုင်း ပါဝင်ကိုက်ညီနေတဲ့ “aaabbb1” နှင့် “abab2” တို့ကို ထုတ်ပြပေးတာတွေ့ရမှာပါ။ “+” Character ဟာ Extended Regular Expression Character ဖြစ်တာမို့ “grep” Command မှာ “-E” Option ထည့်သုံးပေးဖို့လိုပါတယ်။

Meta-characters အများစုဟာ အသုံးပြုရလွယ်ပုံရပေမယ့် ပထမဆုံးအသုံးပြုရာမှာတော့ အခက်အခဲလေးရှိနိုင်ပါတယ်။ အခုပြောသွားတဲ့ ဥပမာတွေဟာ Regular Expressions တွေရဲ့ အလုပ်လုပ်ပုံအနည်းငယ်လေးတွေပါ။ သူတို့ဘယ်လိုအလုပ်လုပ်လဲဆိုတာ ပိုမိုနားလည်နိုင်ဖို့ Meta-characters တွေအားလုံးကို စမ်းသုံးကြည့်ပါ။